🤖 AI 每日资讯
- 📅 日期: 2025/12/5 NaN## 1. LlamaIndex 深度实战:用《长安的荔枝》学会构建智能问答系统
本文深度剖析了 RAG(检索增强生成)系统的工作原理,通过生动的比喻解释了从文档切分、向量化到语义检索和答案生成的全过程。接着,文章以《长安的荔枝》为例,详细演示了如何使用 LlamaIndex 这一数据框架,通过简洁的 Python 代码快速构建一个智能问答系统,并对核心 API 进行了详尽解读。更具价值的是,文章通过一系列严谨的实验,深入探讨了 chunk_size、top_k 和 chunk_overlap 等关键参数对问答质量的影响,提供了不同应用场景下的参数调优建议。最后,文章还对 LlamaIndex 的内部架构进行了组件级拆解,帮助读者全面理解其运行机制,为二次开发打下基础。整体内容理论与实践并重,极具指导意义。
- 标签:
个筛选器
2. 评估深度 Agent:经验总结与分析
这篇来自 LangChain 博客的文章详细介绍了评估“深度 Agent”的五个关键模式,这些 Agent 是复杂的、有状态的 AI 应用。文章强调,传统的 LLM 评估方法通常不足以应对 Agent 的动态特性,并且每个测试用例都需要特定的、与上下文相关的成功标准。为了克服这些限制并确保强大的测试,文章概述了五个关键模式。首先强调为每个数据点定制基于代码的测试逻辑,从而可以针对 Agent 的轨迹、最终响应和内部状态进行特定的断言。其次,提倡使用单步评估作为验证即时决策和工具调用的有效方法,类似于单元测试。第三,完整的 Agent 回合对于提供端到端操作的全面视图至关重要,可用于评估整体轨迹、最终响应和生成的工件。第四,多轮评估模拟了真实的用户交互,但需要条件逻辑来管理 Agent 偏差并确保测试一致性。最后,强调了干净、可复现的测试环境和模拟外部 API 请求的重要性,以确保可靠且高效的评估。文章认为 LangSmith 的测试集成是实现这些模式的灵活框架,为人工智能开发人员提供实用的指导。

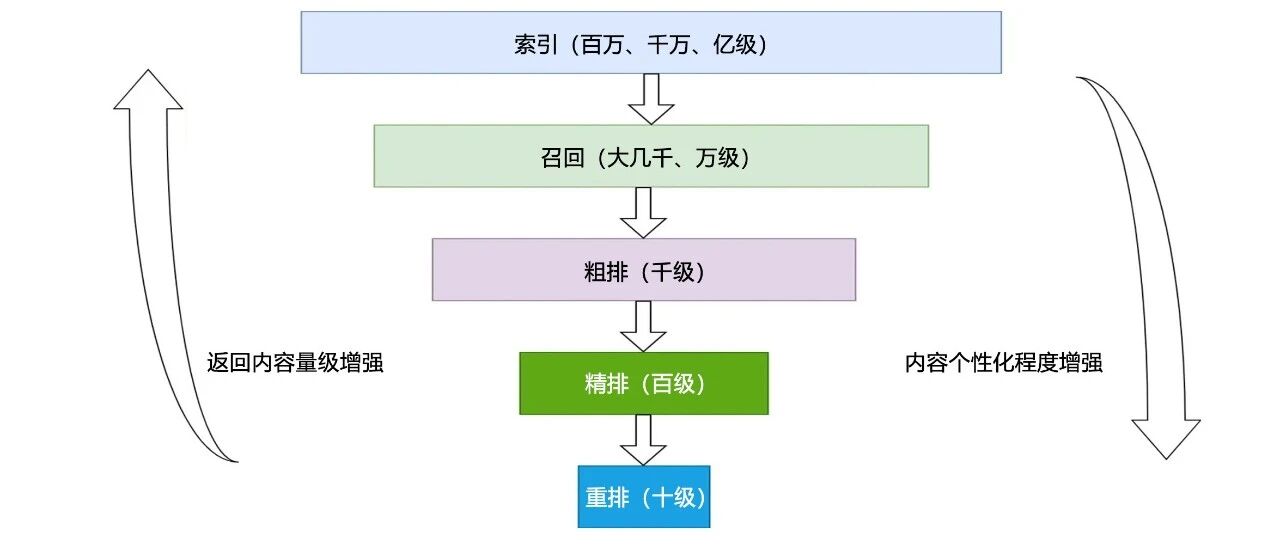
3. 推荐系统三十年:从协同过滤到大模型时代的技术编年史
文章系统地梳理了推荐系统从 1992 年诞生至今的三十余年发展历程。它以时间为轴,详细阐述了四个关键阶段:起源篇(协同过滤的黎明)、发展篇(Netflix Prize 与特征工程时代)、成熟篇(深度学习的全面统治)和未来篇(大模型时代的范式转移)。文中不仅介绍了 Tapestry、GroupLens 等早期系统,矩阵分解、GBDT+LR 等中期技术,以及 Wide & Deep、DIN 等深度学习模型,还深入探讨了大语言模型在生成式推荐、提示学习和 RAG 等新范式下的应用,并分析了 Meta、快手、阿里、字节跳动等公司的最新工业实践。最后,文章总结了数据与算法协同进化、学术与工业相互促进等技术演进的启示,并对从业者提出了建议,展望了推荐系统的未来挑战与方向。
- 标签:
中文
4. Z-Image 零基础上手指南:本地部署 + 提示词模板实战
文章为 Z-Image 这一高效能、轻量化的生成式 AI 模型提供了全面的零基础上手指南。它强调 Z-Image 原生支持中英双语理解与渲染,并解决了低显存设备(如 6GB 显存笔记本)的部署难题。文章从模型下载、ComfyUI 配置、核心组件加载(扩散模型、文本编码器、VAE)到关键采样器参数设置,详细拆解了标准工作流和 GGUF 量化低显存工作流。此外,还提供了电商产品、中英文海报、东方文化等三类高频场景的提示词模板,并总结了图像全黑、文字乱码等常见问题及解决方案。整体内容结构清晰,实操性强,旨在帮助技术从业者快速掌握 Z-Image 的本地应用。

- 标签:
LlamaIndex
5. 深度解构!从 LLaVA 到 Qwen3-VL,多模态大模型主流架构的演进之路
文章深入分析了多模态大模型(MLLM)的发展历程和主流架构。首先,它构建了 MLLM 的“三位一体”黄金架构蓝图,包括视觉编码器(ViT)、大语言模型(LLM)和连接器,并详细阐述了 ViT 的 2D-RoPE、LLM 的 MoE 架构及多种解码策略。接着,文章聚焦于 MLLM 如何处理高分辨率视觉信息的核心挑战,提出了两条截然不同的解决方案:以 LLaVA 系列为代表的“AnyRes”输入端工程优化路线,通过全局与局部拼接或双线性插值处理高分辨率图像;以及以 Qwen3-VL 为代表的“DeepStack”模型内部深度融合路线,其语言模型部分采用了先进的混合专家(MoE)架构,并通过将视觉特征分层注入 LLM 的浅层,实现高效协同。最后,文章对 LLaVA 和 Qwen3-VL 的具体架构进行了全景剖析,并展望了 MLLM 向视觉智能体、动态与三维世界理解以及真正的多模态统一方向发展。
6. 从不足到精进:H5 即开并行加载方案的演进之路
文章深入分析了 H5 即开 SDK 并行加载技术,旨在利用 Native 层提前请求关键资源以加速页面加载。核心挑战在于 WebView 与并行任务间的资源无缝交接。文章首先介绍了早期基于循环探测和全量缓存的方案,指出了其在时间浪费和内存消耗上的局限性。随后,详细阐述了演进方案,通过引入生产者-消费者模型、线程同步机制和桥接流技术,实现了对中间态资源交接的优化,解决了轮询等待和全量缓存问题。最后,针对 Java 内置
synchronized非公平锁导致的线程抢占问题,进一步优化为基于ReentrantLock和Condition的公平锁策略,确保了消费者线程能及时获取资源,显著提升了 H5 页面的加载效率和用户体验。
- 标签:
人工智能
7. 【早阅】10 倍工程:生成式 AI 工具如何转团队生产力
本文深入探讨了团队如何利用生成式 AI 工具实现生产力的大幅提升。文章指出,AI 集成开发环境 Cursor 的出现是关键转折点,它能实际为开发者编写代码,改变了协作模式。通过有机采纳策略,团队实现了 Cursor 的广泛应用。文章还详细介绍了 AI 代理(如 Devin 和 Robo)如何扩展工程能力,自动化中小型任务,并优化新员工入职流程。此外,通过建立“Cursor 规则”和利用 AI 工具(如 Zapier AI)自动化工作流、分析用户反馈,团队在代码质量、沟通效率和数据洞察方面均有显著提升。最后,文章强调了战略性推动 AI 采纳的重要性,并警示了过度依赖 AI 可能带来的工程思维退化风险,呼吁工程师保持代码所有权和批判性思维。
- 标签:
Agent评估方法
8. 从 LLM 到 World Model:为什么我们需要能理解并操作世界的空间智能?
文章指出,尽管大语言模型(LLM)能力惊人,但语言是对三维世界的“有损压缩”,不足以支撑真正的智能。受人类进化历程和 DNA 双螺旋发现等案例启发,李飞飞和 Justin Johnson 等人创立 World Labs,旨在构建能够“理解并操作世界”的空间智能与世界模型。其首款 3D 世界生成模型 Marbl,具备多模态输入和交互式编辑能力,通过 Gaussian Splats 实现高效实时渲染,并正探索将物理引擎与生成模型结合。Marbl 的应用场景广泛,涵盖创意影视、室内设计,并被视为机器人和具身智能未来发展的重要基础设施。文章还探讨了算力垄断时代学术界的角色,呼吁其聚焦“蓝天研究”,探索超越现有硬件限制的未来计算架构。
- 标签:
LangChain
9. WebAssembly 在企业应用:安全、便携与商业化准备
本文深入探讨了 WebAssembly (Wasm) 对于企业应用的变革潜力,尤其是在与广泛应用的 Java 虚拟机 (JVM) 集成时。文章强调了 Wasm 作为浏览器中一种快速、安全和便携的二进制格式的起源,并将其优势扩展到服务器端执行。核心论点是,相较于使用外部函数接口(FFI)可能损害 JVM 的安全性、可移植性和可观察性,直接在 JVM 中使用 Chicory(Red Hat 首席工程师 Andrea Peruffo 维护的纯 Java Wasm 运行时)运行 Wasm 更具优势。通过 JRuby (Ruby 解析器)、Trino (Python 用户自定义函数)、Debezium (Go SMTs) 和 SQLite 等详细案例,作者展示了 Chicory 的提前编译 (AOT) 编译器,结合 wasi-vfs 和 Wizer 等工具,以及优化的内存管理(预分配、延迟字段访问)如何显著提高性能并解决常见的集成挑战。结论强调了 Wasm 适用于安全、多语言、高性能插件系统和具有稳定 API 的受限问题域,并将其定位为未来企业架构的关键技术。

10. GenAI 安全:防御深度伪造和自动化社会工程
这篇文章是一个播客的文字稿,由 Wes Reisz 和 Reken 的 CEO Shuman Ghosemajumder 讨论了 GenAI 时代数字信任的紧迫挑战。他们强调了网络犯罪的指数级转变,其中生成式人工智能使犯罪分子能够大规模地模拟人类行为,同时对数百万个目标发起高容量的攻击。Ghosemajumder 解释了 GenAI 如何通过自动化高质量的跨语音和视频的社会工程,绕过传统上依赖人工的防御,从而解决了欺诈者的“最终环节”问题。讨论的一个关键漏洞是“Gell-Mann 失忆症”效应,即用户隐式地信任自信的 LLM 输出,使他们容易受到虚假信息的影响。该播客还探讨了 AI 生成的代码的挑战和风险,强调需要仔细监督和高级开发人员的监督,以管理代码质量和潜在的缺陷。为了应对这些威胁,讨论提倡一种“零信任 (Zero Trust) 架构”,利用行为遥测来检测细微的异常,并应用博弈论来优先考虑安全预算,以对抗经济动机的犯罪。对话强调了创建深度伪造的容易程度,以及人工智能生成内容在互联网上的普遍性。因此,工程师需要构建超越默认信任的系统。

- 标签:
中文
**