- 📅 日期: 2025/12/2
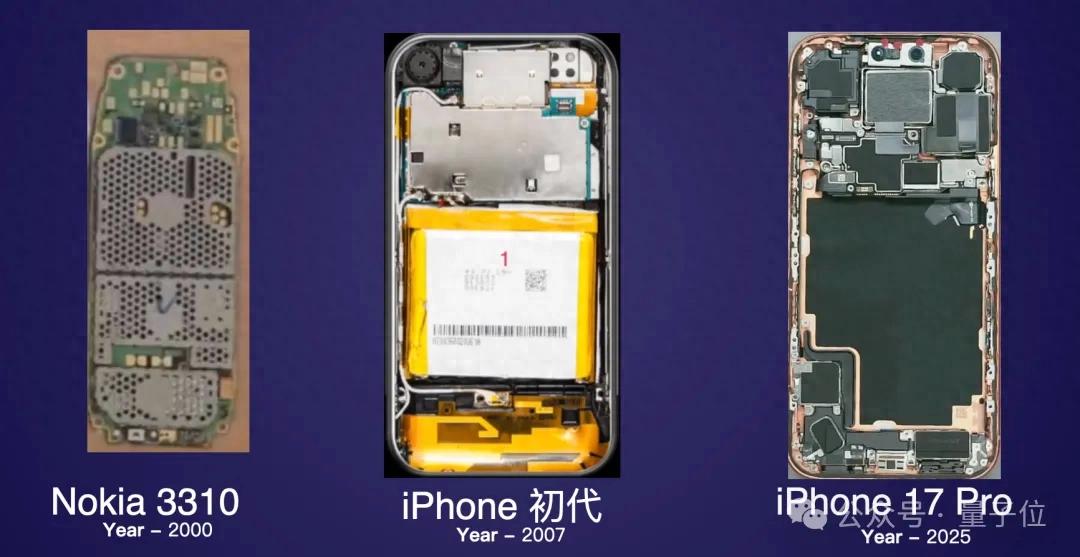
1. 前端没死,AI APP 正在返祖
文章引用蚂蚁集团终端技术委员会负责人翁欣旦的观点,指出 AI 并未杀死前端,而是将技术复杂度从物理堆叠迁移至数字堆叠。AI 应用界面看似“返祖”的极简背后,是交互模式从 CUI 到 GUI 再到 CUI 与 GUI 共生的轮回,以及架构从宽泛 API 到语义化 API 的演进,这实则是在“清算技术债”。文章进一步强调,云端万能论忽略了网络和算力的物理限制,未来 AI 体验将是“云侧训练 + 端侧推理”的混合模式,使终端成为边缘计算强节点。最终,文章指出前端工程师的价值在于对体验的极致敏感度和对抗熵增的工程能力,这些是 AI 无法替代的护城河,为前端从业者指明了方向。
- 原文链接: 阅读原文
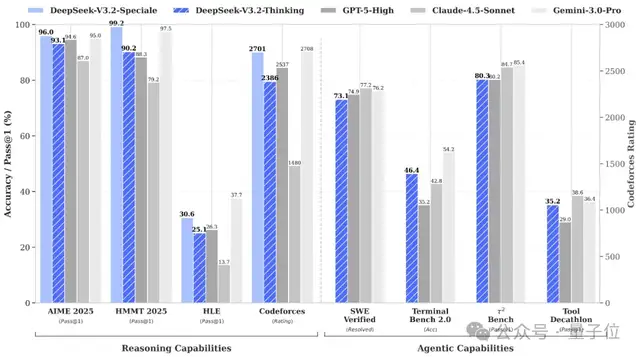
2. DeepSeek V3.2 正式版:强化 Agent 能力,融入思考推理
DeepSeek 正式发布了两款具有里程碑意义的大语言模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。DeepSeek-V3.2 旨在平衡卓越推理能力与高效输出长度,特别适用于日常问答和通用 Agent 任务,在公开推理 Benchmark 中已达到 GPT-5 水平,且相比同类模型显著降低了计算开销和用户等待时间。DeepSeek-V3.2-Speciale 则将开源模型的推理能力推向极致,通过结合 DeepSeek-Math-V2 的定理证明能力,在数学、代码与通用领域评测集上表现媲美 Gemini-3.0-Pro,并成功斩获多项国际奥赛金牌。文章重点强调了 DeepSeek-V3.2 的一项创新:首次将思考模式与工具调用深度融合,通过大规模 Agent 训练数据合成方法,大幅提升了模型在复杂任务上的泛化能力,使其在智能体评测中达到开源模型的最高水平。两款模型均已开源,并通过官方网页端、App 和 API 提供服务,V3.2-Speciale 还提供了临时 API 服务供社区评测与研究。

- 原文链接: 阅读原文
3. 从 CoT 到 AGI:深扒大模型 LLM“深度思考”的技术演进
文章详细探讨了大型语言模型(LLM)“深度思考”能力的起源与发展,从机器思考的本质、Transformer 架构的微观结构与参数规模的重要性入手。接着,阐述了深度思考减少幻觉的必要性,并详细介绍了 CoT 及其变体等外部引导方法。核心篇幅深入分析了基于人类反馈的强化学习(RLHF),对比了 PPO、DPO 和 GRPO 等主流算法的优劣,并对 RLHF 的局限性进行了批判性反思。最后,展望了原子性思考、分层/递归推理模型(HRM/TRM)以及外挂推理知识库(Training-Free GRPO)等前沿方向,为 LLM 的未来发展提供了深刻见解和多种可能性。

- 标签:
AI应用
4. AI 时代,到底会有什么新职业?
本文由腾讯研究院资深专家吴朋阳撰写,详细探讨了 AI 时代对就业市场的深远影响。文章首先阐述了 AI 对劳动力影响的“增强、替代、补充、创造”四大效应,指出当前替代效应快于创造效应,但强调替代不等于失业。接着,通过对全球领先 AI 公司招聘信息的统计分析,将 AI 新职业划分为“使能者、协作者、治理者、推广者、支持者”五大核心类型,并提供了具体岗位实例。文章还总结了 AI 新职业的“深度细分、跨界融合、人机协作、动态流变”四大特征。展望未来,文章预测职业增长将主要出现在“AI 原生”领域、服务业以及“一人企业和灵活就业群体”。最后,文章从个人、企业和社会三个层面提出了积极适应 AI 变革的启示与建议,强调终身学习、构建人机协作模式和搭建就业友好制度环境的重要性。

5. 深度思考:聊聊 AI 发展趋势
该文章由一位资深前端开发者撰写,回顾了 AI 从 AlphaGo 到 ChatGPT 的爆发历程。作者结合自身成功将 ChatGPT 套壳为桌面应用(获得 54k+ Stars)的实践经验,深刻洞察并分享了对 AI 发展趋势的思考。文章首先批判了当前“AI 泛滥”现象中存在的利用信息差和贩卖焦虑的行为。随后,作者将 AI 形态分为模型和使用两部分,重点分析了 AI 应用从网页到桌面应用、CLI 工具,直至 AI 浏览器的演进,指出其核心趋势是“深度集成,弱化权限边界”。在技术实现层面,作者详细比较了 Electron 与 Chromium 二次开发在构建 AI 浏览器时的优劣,并提出未来需要一套“为 AI 量身定制的浏览器 API 层”。最后,文章针对信息过载时代如何有效学习给出了建议,强调问题驱动、靠近一手信息源和主动输出的重要性。

- 标签:
人工智能
6. DeepSeek-V3.2 系列开源,性能直接对标 Gemini-3.0-Pro
文章深入介绍了 DeepSeek 团队最新开源的 DeepSeek-V3.2 系列大模型。DeepSeek-V3.2 聚焦平衡实用,擅长通用 Agent 任务和工具调用,Agent 评测达开源模型最高水平;DeepSeek-V3.2-Speciale 则主打极致推理,融合数学定理证明能力,推理基准性能媲美 Gemini-3.0-Pro,适用于复杂数学和编程竞赛。核心技术创新包括引入 DSA(DeepSeek Sparse Attention)机制,将长序列计算复杂度降至 O(L·k),显著降低推理成本。此外,团队在强化学习(RL)训练上投入巨大,计算预算超预训练成本 10%,并开发了稳定可扩展的 RL 协议。在 Agent 任务方面,通过新颖的上下文管理、巧妙的 prompt 设计和自动环境合成管线,模型泛化能力显著增强。尽管世界知识广度和 Token 效率仍有提升空间,但这些模型为开源 AI 社区带来了重要突破。
- 标签:
大语言模型
7. Claude 4.5 Opus 的“灵魂文档”
本文详细介绍了 Anthropic 在 Claude 4.5 Opus 的训练中使用的一份开创性的“灵魂文档 (soul document)”的发现和后续确认过程。该文档最初由 Richard Weiss 发现,作为模型提取的系统消息中一致的“soul_overview”部分,其真实性后来得到了 Anthropic 的 Amanda Askell 的验证。该文档在监督学习期间被整合,旨在使 Claude 秉承 Anthropic 的核心使命:开发安全、有益和可理解的人工智能。它强调培养良好的价值观、全面的自我知识以及模型在各种情况下安全行事所需的智慧。此外,该文档明确提到了提示注入攻击,从而解释了为什么 Claude Opus 对此类攻击表现出改进的(尽管仍然脆弱的)抵抗力。这一揭示为尖端大语言模型开发中采用的先进的伦理对齐和个性塑造技术提供了一个引人入胜的视角。
- 标签:
模型推理
8. 马斯克信息量炸裂的最新访谈: AI, 意识与未来的重构 | 3 万字全文图解+视频+ 语音总结
本文是对埃隆·马斯克最新访谈的深度总结,涵盖其对未来世界的宏大愿景。访谈内容包括 X 平台作为全球集体意识的构建、特斯拉、SpaceX 和 xAI 的技术融合以实现深空探索。马斯克预测 AI 将带来“普遍高收入”的后工作社会,并强调 AI 发展需遵循真理、美和好奇心三大伦理原则。他还表达了对人口下降的深切担忧,认为其威胁文明意识的扩张。最后,马斯克向年轻创业者建议,应专注于成为社会的“净贡献者”,而非直接追逐金钱或幸福。文章全面呈现了马斯克在科技、经济、社会和哲学层面的多维度思考。
9. 微软 CEO 纳德拉最新访谈,信息量很大!
微软 CEO 萨提亚·纳德拉与 Stripe 联合创始人约翰·科里森的深度对话,揭示了微软在 AI 浪潮下的战略思考与布局。纳德拉强调知识图谱将成为企业 AI 应用的“杀手级”应用,并详细阐述了 Agent 模型的三大基石(记忆、权限、行动空间)和微软 AI 技术栈的三层架构。文章回顾了微软差点错失互联网的教训,指出范式正确不代表必然成功,并警示新的“组织层”聚合力量。他提出未来公司核心主权在于拥有吸收自身隐性知识的模型,并展望了跨工作流软件、智能体电商以及由“模型选择器”驱动的多模型阵列。最后,纳德拉分享了其 CEO 工作重心,强调与客户和开发者沟通的重要性,以及通过提供一致叙事和赋能团队来塑造企业文化。